고정 헤더 영역
상세 컨텐츠
본문
- 9월 18일
합성곱 신경망의 개념과 구현에 대해 배운다.
합성곱 신경망은 이미지데이터에 적합한 인공지능 모델이다. 왜 그런지 알아보자
합성곱 신경망(CNN)
합성곱은 fully connected 신경망과는 계산이 조금 다르다. 하나의 뉴런에 대하여 입력데이터 전체에 가중치를 곱하는게 아니라 '일부만' 가중치를 곱한다.
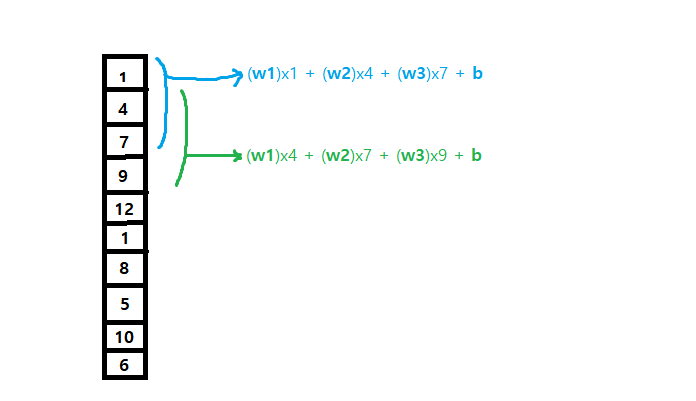
예를들어 입력 데이터가 100개라면, 1~n번째 까지의 선형회귀 방정식을 만들어 출력을 하고, 그 다음에는 2~(n+1)번째 까지의 선형회귀 방정식을 만들어 출력을 한다. 여기서 각 횟수마다 사용되는 가중치와 절편값은 모두 동일하다!
-> 물론 여기서 언급한 n도 하이퍼파라미터다.
(용어) 합성곱 신경망에서는 뉴런이라는 용어 대신 필터나 커널이라는 단어를 쓴다.
keras API에서는 뉴런 갯수에 대해서는 filter라고 부르고, 가중치에 대해서 언급할 떼는 kernel이라고 부른다.
합성곱 신경망의 작동 원리

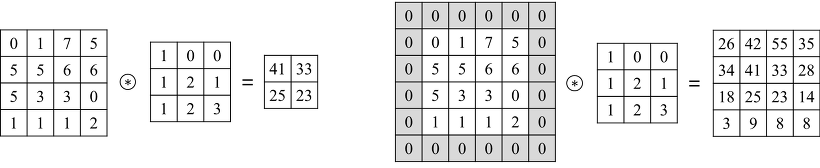
n차원의 입력행렬이 주어지면, 동일한 차원의 더 작은 필터를 이용해, 둘이 서로 겹칠 수? 있는 모든 경우에 대해서 합성곱(*)을 수행하고 결과를 출력행렬의 원소에 넣는다. (각 합성곱 연산마다 절편 값을 더하는 것을 잊으면 안 된다!)
합성곱 연산이란
| 1 | 3 | 2 |
| 6 | 5 | 4 |
| 7 | 9 | 8 |
| 3 | 1 | 2 |
| 4 | 5 | 6 |
| 8 | 7 | 9 |
다음과 같은 두 3x3행렬이 있다고 하자. 합성곱 연산이란 행과 열의 번호가 같은 두 원소를 서로 곱하고 모두 더하는 연산을 말한다.
위 예시의 합성곱 결과는 다음과 같다.
1x3 + 3x1 + 2x2 +
6x4 + 5x5 + 4x6 +
7x8 + 9x7 + 8x9
이렇게 CNN을 통해 얻은 행렬을 따로 특성 맵(feature map)이라고 부른다.
Tip) 동일한 입력벡터에 대해 서로 다른 필터들을 적용해서 각 특성맵들을 하나의 행렬로 합칠 수도 있다. 이러면 당연히 합쳐진 하나의 행렬은 차원이 하나 증가한다.
Why?) 왜 이미지데이터에는 합성곱 신경망이 좋은 효율을 내는가?
그 이유는 CNN은 2차원(1차원 이상) 행렬을 그대로 유지한 채 연산이 가능하기 때문이다. 이미지란 각 특성(픽셀)마다 좌우 뿐만 아니라 "인접한" 상,하,좌,우,대각선 모두 연관되어 있는데, 1차원으로 쭉 늘어뜨려버리면 인접한 데이터들이 잘 적용되지 않기 때문이다.
keras CNN
keras패키지에는 CNN을 지원하는데, 다음과 같이 사용한다. 함수이름과 매개변수들을 제외하면 이전의 Dense함수와 거의 동일하게 역할을 한다.
keras.layers.Conv2D(<num_of_filter>, kernel_size = <dimension>, activation = <str>)
num_of_filter는 필터의 갯수를 말한다. 2개 이상이면 서로다른 가중치를 갖는 필터가 존재한다는 뜻이다.
kernel_size는 필터(커널)의 사이즈를 결정한다. (3, 3)이라고 지정하면 필터 사이즈는 3x3 행렬이다.
activation은 필터를 통과한 element에 적용할 활성화 함수를 선택한다.
패딩과 스트라이드
패딩
패딩이란 원래의 행렬을 가상의 원소들로 겉으로 둘러싸는 작업을 말한다.
구조적으로는 특성 맵의 행, 열 크기를 조정하는 것이다.
패딩은 중심부 뿐만 아니라 가장자리의 element들도 골고루 반영하기 위해 사용된다.
-> 패딩되는 가상의 원소들은 원래 행렬에 영향을 주어선 안되기 때문에 0으로 채운다.
(용어) 이렇게 패딩과정을 거칠 때 패딩값을 전부 0으로 하고 합성곱 연산을 하는 것을 same padding이라고 하고, 패딩과정을 거치지 않고 합성곱 연산을 하는 것을 valid padding이라고 한다.
패딩을 keras에서 적용하는 방법은, Conv2D함수의 매개변수로 padding을 사용하는 것이다.
keras.layers.Conv2D(..., padding = <str>)
same padding은 <str> 부분에 "same"이 들어가고, valid padding(기본값)은 "valid"가 들어간다.
스트라이드
스트라이드란 합성곱을 적용하는 부분의 step을 말한다. 위의 예제에서는 합성곱을 할 때마다 필터를 한 칸씩 이동했는데, stride = 2로 한다면 두 칸씩 이동할 것이다.
Why?) 스트라이드를 왜 사용하는가?
이유는 패딩을 사용하는 이유와 매우 비슷하다.
구조적으로는 특성 맵의 행, 열 크기를 조정하는 것이다.
스트라이드는 각 element들을 골고루 반영하기 위해 사용된다. 스트라이드가 클 수록 한 element가 필터링 되는 횟수가 감소한다.
하지만 스트라이드를 2 이상으로 하는 것은 실무에서 그다지 잘 사용되진 않는다고 한다.
스트라이드 역시 keras에서는 Conv2D함수의 매개변수로 strides를 사용한다.
keras.layers.Conv2D(..., strides = <n>)
기본값은 1이다.
풀링
풀링이란 CNN의 결과로 나온 특성 맵의 차원의 크기를 줄이는 작업을 말한다.
특성 맵의 갯수 자체는 감소시키지 않는다.
풀링은 특성 맵을 입력으로 하고, 필터처럼 이동하면서 연산을 수행하지만, 각 element가 한 번만 연산이 수행되도록 strides가 자동 지정되며, 연산이 합성곱이 아니라 각종 통계연산(평균, 최댓값 찾기 등)을 수행한다.
(용어) 특성 맵을 입력으로 받아 풀링 과정을 거친 출력행렬도 역시 특성 맵이라고 부른다.
일단 최대값 풀링과 관련된 keras 함수는 다음과 같다.
keras.layers.MaxPooling2D(<size_of_pooler>)
보통 2를 사용하여 크기를 절반으로 줄인다.
풀링은 최대풀링(MaxPooling)이 가장 잘 사용된다.
합성곱 신경망의 전체 구조

하나의 입력행렬을 학습/예측 하는 과정은 다음과 같다.
1. 입력행렬을 1개 이상의 필터로 합성곱을 한다. 합성곱을 했으면 풀링을 통해 크기를 줄인다. 상황에 따라 적절한 단계에 특성 맵들을 하나로 합친다. 패딩여부와 크기는 알아서 선택한다.
2. CNN작업이 끝난 최종 특성맵들을 1차원으로 늘어뜨린 뒤 fully connected 신경망을 통과시켜 과정을 완료한다.
즉 CNN -> fully connected 신경망 순서이다.
Tip) 행렬의 크기를 줄일 때, 스트라이드를 크게 하여 줄이는 것보다 풀링을 통해 줄이는 것이 일반적으로 더 나은 성능을 보인다.
(주의!) 위에도 언급했지만, 각 합성곱 연산마다 절편값이 추가됨을 잊지말자.
Tip) 입력행렬 자체가 3차원이라면?
상상이 잘 안가겠지만, 입력행렬이 2차원이 아닌 3차원 형식이라면, 필터도 3차원이 된다.
물론 2차원때랑 똑같이 하나의 합성곱은 하나의 element가 나온다(스칼라).
e.g.) 흑백이미지는 2차원, 컬러이미지는 3차원으로 표현된다. 그러나 keras 내부적으로는 2차원 행렬은 깊이갯수가 1인 3차원으로 변환하여 연산한다.
합성곱 신경망의 일반적인 구조
이미지를 처리하기 위해 CNN알고리즘을 이용한다면, 처음에는 필터의 갯수를 적게하여 직선, 곡선같은 주요 특징을 잡아낸다. 층이 깊어질 수록 필터의 갯수를 늘려서 디테일을 구별할 수 있게 한다.
합성곱 신경망 구현
완전 연결 신경망과 구현 측면에서의 차이점은 다음과 같다.
1. Dense함수 대신 Conv2D함수 사용
2. MaxPooling2D함수 사용
3. 데이터 묶음을 reshape할 때 (데이터갯수, 데이터 가로, 데이터 세로, 데이터 깊이) 이렇게 4차원으로 reshape한다!
-> 완전 연결 신경망 때에는 (데이터 갯수, feature갯수) 이렇게 2차원으로 reshape했다.
나머지는 완전 연결 신경망 구현과 완전히 동일하다.
# 필요한 패키지들을 import하기
from tensorflow import keras
from sklearn.model_selection import train_test_split
# keras 자체에 내장되어 있는 데이터셋인 fashion_mnist를 사용하기로 함
(train_input, train_target), (test_input, test_target) =\
keras.datasets.fashion_mnist.load_data()
# 훈련 데이터를 CNN에 맞게 구조변형 and 값 scaling하기
train_scaled = train_input.reshape(-1, 28, 28, 1) / 255.0
# 전체 데이터를 split하기
train_scaled, val_scaled, train_target, val_target = train_test_split\
(train_scaled, train_target, test_size=0.2, random_state = 42)
# 빈 모델 생성하기
model = keras.Sequential()
# 첫 층에 CNN을 추가하기
model.add(keras.layers.Conv2D(32, kernel_size = 3, activation = "relu", padding = "same", input_shape = (28, 28, 1)))
model.add(keras.layers.MaxPooling2D(2))
# 두번째 층에도 CNN을 추가하기
model.add(keras.layers.Conv2D(64, kernel_size = 3, activation = "relu", padding = "same"))
model.add(keras.layers.MaxPooling2D(2))
# 세번째 층부터 fully connected 신경망을 따른다
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation = "relu"))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation = "softmax"))
# 모델 구성이 끝났으니 compile 먼저 하기
model.compile(optimizer = "adam", loss = "sparse_categorical_crossentropy", metrics = "accuracy")
checkpoint_cb = keras.callbacks.ModelCheckpoint("best-cnn-model.h5", save_best_only = True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience = 2, restore_best_weights = True)
# 드디어 학습시키기
history = model.fit(train_scaled, train_target, epochs = 20, validation_data = (val_scaled, val_target), callbacks = [checkpoint_cb, early_stopping_cb])참고: 혼자 공부하는 머신러닝+딥러닝
Tip) 파이썬에서 코드가 너무 옆으로 길 때에는 역슬래시(\)를 사용해서 코드를 잘라서 밑으로 넣을 수 있다.
keras.utils.plot_model(model[, show_shapes = T/F])
모델구조를 시각적으로 표현해 준다. show_shapes를 True로 한다면 입출력 데이터의 형태도 같이 표기해 준다.
'PLAYDATA > PLAYDATA데일리노트' 카테고리의 다른 글
| [PLAYDATA] 데이터 엔지니어링 9월 4주차 9/19 (0) | 2023.09.19 |
|---|---|
| [PLAYDATA] 데이터 엔지니어링 9월 3주차 9/16 (0) | 2023.09.16 |
| [PLAYDATA] 데이터 엔지니어링 9월 3주차 9/15 (0) | 2023.09.15 |
| [PLAYDATA] 데이터 엔지니어링 9월 3주차 9/14 (0) | 2023.09.14 |
| [PLAYDATA] 데이터 엔지니어링 9월 3주차 9/13 (0) | 2023.09.13 |




