고정 헤더 영역
상세 컨텐츠
본문
- 8월 30일
dataframe에 행, 열을 추가/변경/삭제하는 법을 알아보고 numpy에 대해 잠깐 배운다.
특정 인덱스 이름 변경하기
df_name.rename(index=<dict>, inplace=T/F)
Dictionary의 key는 기존이름, value는 바꿀 이름이다.
데이터에 함수 적용하기
데이터프레임의 데이터들에게 함수 연산을 적용할 수 있다.
(주의!) 함수의 첫 번째 argument는 묵시적으로 apply함수를 호출한 DataFrame또는 Series가 된다. 그리고 함수가 Parameter로 받을 때 첫 번째 parameter는 반드시 Series로 변환된다. (Dataframe으로 받으면 series로 쪼개져서 각각 따로 함수가 호출된다는 뜻)
-> 쉽게 말해 apply함수를 호출한 대상이 Series를 하나만 가지고 있다면 해당 series가 첫번째 함수 인자로 가고, series를 두개 이상 가지고 있는 dataframe이면 dataframe을 각각 series로 쪼갠 뒤 각각 따로 함수를 호출하는 형태이다.
(axis=0이면 열 단위로 쪼갬, axis=1이면 행 단위로 쪼갬)
(주의2!) drop의 axis옵션과 행동이 반대이니 조심하기!
df_name.apply(<func_name>[, axis=0/1], <argu1_name> = <argu1_value>, <argu2_name> = <argu2_value>, ...)
예제)
import pandas as pd
def columnsum(x):
return x["x1"]+x["x10"]+x["x100"]
#return x.sum()으로 사용할 수 있다.
def rowsum(y):
return y[0]+y[1]+y[2]
#return y.sum()으로 사용할 수 있다.
_2dlist = [
[1,10,100],
[2,20,200],
[3,30,300]
]
df2 = pd.DataFrame(_2dlist, columns=["x1", "x10", "x100"])
df2["sum"]=df2.apply(columnsum, axis = 1)
print(df2)
print("\n")
df2.drop(["sum"], inplace=True, axis=1)
print(df2)
print("\n")
df2.loc["sum2"] = df2.apply(rowsum)
print(df2)결과)
더보기
x1 x10 x100 sum
0 1 10 100 111
1 2 20 200 222
2 3 30 300 333
x1 x10 x100
0 1 10 100
1 2 20 200
2 3 30 300
x1 x10 x100
0 1 10 100
1 2 20 200
2 3 30 300
sum2 6 60 600apply함수가 최종적으로 어떤 것을 반환하는지(행 반환인지, 열 반환인지) 인지해야 한다. 반환 자료형에 따라서 대입의 대상이 df의 행이 될 수도 있고 열이 될 수도 있다.
Tip) 보통 apply함수에 적용되는 함수는 Series를 인자로 받아서 연산하고 return 자료형은 단일 데이터이다.
numpy라이브러리
numpy라이브러리란 수학/과학 연산을 지원하는 라이브러리다. numpy를 통해 방정식이나 함수 등 수학적 연산을 편리하게 할 수 있다.
여기서는 일단 NULL값에 대응되는 NaN을 사용하기 위해 numpy라이브러리를 이용한다.
numpy라이브러리는 다음과 같이 import한다
import numpy as np
관습적으로 np라고 사용한다.
결측치
결측치는 데이터가 존재하지 않는 것을 의미한다.
numpy를 이용해서 다음과 같이 사용한다.
np.nan
결측치 유무 확인
df_name.isnull()
데이터프레임의 각 데이터가 T/F값으로 채워진다.
isnull() 뒤에 .sum()을 붙이면 각 열이 NaN을 얼마나 가지고 있는지를 Series형태로 반환한다.
결측치가 1개이상 포함된 행/열 모두 삭제
df_name.dropna([axis=0/1])
axis=0이면 행을 기준으로 삭제 (디폴트)
axis=1이면 열을 기준으로 삭제
결측치 채우기
df_name.fillna(<특정값 | method="ffill"/"bfill" | <dict>>)
예시)
df.fillna(0)
모든 NaN을 0으로 채우기
df.fillna(method="ffill")
a. NaN이 한개 또는 두개 이상 연속적으로 있을 때, 첫번째 NaN바로 앞 데이터로 채운다.
b. bfill일 경우엔 마지막 NaN바로 뒤 데이터로 채운다.
df.fillna({'A':0, 'B':1, 'C':2, 'D':3})
각 column마다 지정된 값으로 NaN을 채운다. key는 column이름, value는 채울 값이다.
참고) NaN 데이터는 average같은 통계적 계산에서 배제시킨다.
자료형
자료형 확인
df_name.dtypes
s_name.dtype
참고) 한 시리즈에 두가지 이상의 자료형이 혼합되어 있으면 object로 표시된다.
한 시리즈에 정수와 실수가 혼합되어 있으면 float64로 표시된다.
자료형 변환
df_name.astype(<datatype>)
s_name.astype(<datatype>)
특정 시리즈의 요소를 전부 숫자형으로 변경하기
pd.to_numeric(<dataframe | series>, errors=<ignore | coerce | raise>)
스칼라값, list, tuple도 가능하다. DataFrame은 안되니 주의!
ignore: 숫자 변환이 불가능한 데이터는 무시
coerce: 숫자 변환이 불가능한 데이터는 NaN으로 변환
raise: 숫자 변환이 불가능한 데이터는 오류발생
카테고리 자료형
카테고리 자료형은 정수형 데이터들을 그룹화 시키는 기능을 하는 자료형이다.
쉽게말해 카테고리 목록이 A, B, C가 있으면 A는 0~20, B는 21~40, C는 41이상 이라는 식으로 정수들을 묶을 수 있다.
카테고리 기능에는 .categories와 .codes가 있다.
.astype("category")로 만들 수 있다.
카테고리 변경/추가
<column_name>.cat.set_categories(<list>)
카테고리가 <list>대로 변경된다.
<column_name>.cat.add_categories(<list>)
카테고리 목록 끝에 새 카테고리를 추가한다.
안쓰는 카테고리 제거
<column_name>.cat.remove_unused_categories()
데이터프레임 연결하기
데이터프레임을 서로 가로 또는 세로로 붙일 수 있다.
pd.concat(<list>[, axis=0/1])
<list>에는 데이터프레임을 요소로 하는 list자료형이 들어간다.
axis=0이면 세로로 붙이고 axis=1이면 가로로 붙인다. (디폴트는 0)
만약 접합면에서 크기 차이가 발생하면 더 길이가 짧은 부분은 모두 NaN으로 채워진다.
데이터프레임 병합하기
데이터프레임을 병합한다. (SQL의 JOIN기능과 유사)
pd.merge(<df_name1>, <df_name2>
[, how=<inner | outer | left | right>]
[, left_on=<column_name>]
[, right_on=<column_name>]
[, on=<column_name> | None]
)
옵션들의 기본값은 how="inner", on=None이다.
how 옵션
inner: 특정 열을 기준으로 데이터가 동일한 행끼리만 묶어서 출력
outer: 특정 열을 기준으로 두 데이터테이블의 모든 행을 반영하되, 없는 데이터는 NaN으로 결정
left: 왼쪽 데이터테이블은 고정시키고 오른쪽 테이블이 거기에 맞춘다. (오른쪽 테이블에 없는 요소는 NaN으로 채움)
right: 오른쪽 데이터테이블은 고정시키고 왼쪽 테이블이 거기에 맞춘다. (왼쪽 테이블에 없는 요소는 NaN으로 채움)
on/left_on/right_on 옵션
병합의 기준이 되는 열 2개를 선택하는 옵션이다. 디폴트로는 on=None이며, 이는 양쪽 데이터테이블에서 맨 첫번째 열을 선택한다는 의미이다.
on: 두 데이터테이블에서 merge에 쓰일 기준 열을 선정한다. (즉 두 테이블 모두 서로 동일한 이름을 가진 열이 하나 이상은 있어야 한다.)
left_on: 왼쪽 데이터테이블에서 merge에 쓰일 기준 열을 선정한다.
right_on: 오른쪽 데이터테이블에서 merge에 쓰일 기준 열을 선정한다.
(주의!) on 옵션과 left/right_on 옵션은 동시에 존재할 경우 논리적 모순이기 때문에 on옵션만 쓰든가 아니면 left_on과 right_on 옵션을 쓰든가 둘 중 하나만 선택해야 한다.
행, 열 변형하기
행, 열 변형은 데이터 전처리 과정에서 자주 쓰이는 방법이다.
pd.melt
id_vars 옵션에 넣지 않은 column들을 variable과 value라는 새로운 열에 쭉 나열하는 방법이다.
id_vars 옵션에 포함된 열들의 목록마다 id_vars에 포함되지 않은 "하나의" 열이 값과 함께 세로로 나열된다.
예제)
| x1 | x2 | x10 | x100 | |
| 0 | 1 | 2 | 10 | 100 |
| 1 | 3 | 6 | 30 | 300 |
| 2 | 4 | 8 | 40 | 400 |
| 3 | 6 | 12 | 60 | 600 |
| 4 | 7 | 14 | 70 | 700 |
데이터테이블 이름은 df3이라고 하자.
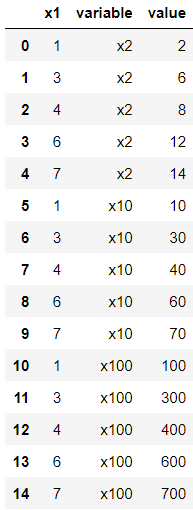
pd.melt(df3, id_vars=["x1"])
를 적용한 모습이다.
df.pivot
pivot table이란 데이터프레임의 columns 중에서 두 개의 column을 각각 행 인덱스, 열 인덱스로 사용하는 table이다.
즉 피벗테이블이란 두 개의 열을 기준으로 하나의 열을 데이터테이블 형식으로 배치해 놓은 테이블이다.
사용 방법은 다음과 같다.
df_name.pivot(<column_name_for_column_index>, <column_name_for_row_index>, <column_name_for_data>)
특징이 있다면, 기준이 되는 두 개의 열에 대해서, 각각의 경우의수에 대해 데이터대상의 열 값이 하나만 존재한다면 결과테이블은 대각행렬 형태이다.
예시)
| x1 | x2 | x10 | x100 | |
| 0 | 1 | 2 | 10 | 100 |
| 1 | 3 | 6 | 30 | 300 |
| 2 | 4 | 8 | 40 | 400 |
| 3 | 6 | 12 | 60 | 600 |
| 4 | 7 | 14 | 70 | 700 |
데이터테이블 이름은 df3이라고 한다.

df3.pivot("x1", "x2", "x10")
를 실행한 결과이다.
df.transpose
행을 열로, 열을 행으로 바꾼다. 행렬 개념에서의 그 transpose가 맞다.
df_name.transpose()
'PLAYDATA > PLAYDATA데일리노트' 카테고리의 다른 글
| [PLAYDATA] 데이터 엔지니어링 9월 2주차 9/5 (0) | 2023.09.05 |
|---|---|
| [PLAYDATA] 데이터 엔지니어링 8월 5주차 8/31 (0) | 2023.08.31 |
| [PLAYDATA] 데이터 엔지니어링 8월 5주차 8/29 (0) | 2023.08.29 |
| [PLAYDATA] 데이터 엔지니어링 8월 5주차 8/28 (0) | 2023.08.28 |
| [PLAYDATA] 데이터 엔지니어링 8월 4주차 8/25 (0) | 2023.08.28 |




